
Description
Ollama allows running LLM models locally. We did not test all the models, so some models may not work properly. "Thinking" models, like Deepseek R1, are not currently supported. The full list of ollama models is available here
The list of tested models (May 2025)
gemma3 and aya seem to be a good choice.
Setup
- Install Ollama
- Download LLM model you want to use by running
ollama run {ModelName}command. Make sure your hardware meets requirements for running this model locally. -
Go to Configuration->Locale and add a string field with
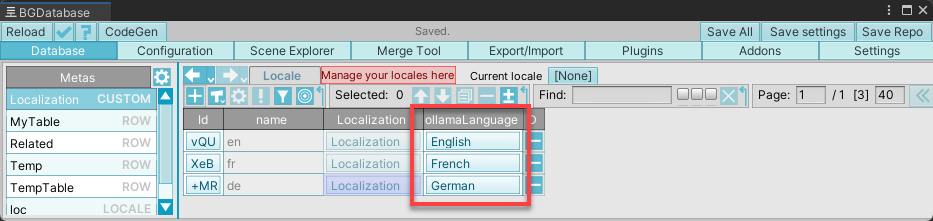
ollamaLanguagename
-
Navigate to Settings->Translation and enter Ollama URL and Ollama model parameters
Then click on "Load the model and check connection" button to verify that everything is set up correctly.

- Go to Database->Localization and for each locale fill "ollamaLanguage" field with the right language.
The list of supported languages may take some time to load.
-
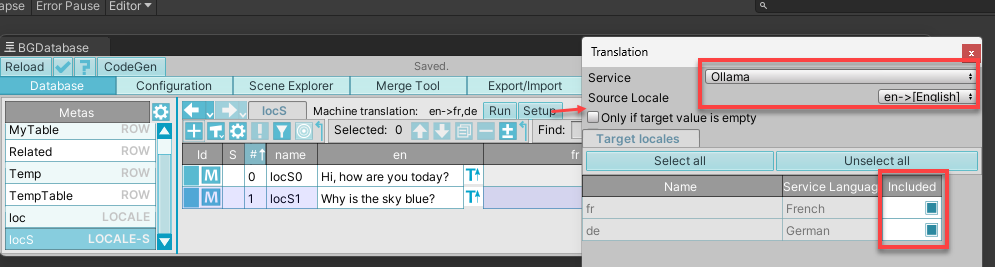
Choose any table with "localization" (Locale) or "localizationSingleValue" (Locale-S) types and string/text field type.
Click on Setup and choose Ollama as translation service.
Choose your source language and destination languages.
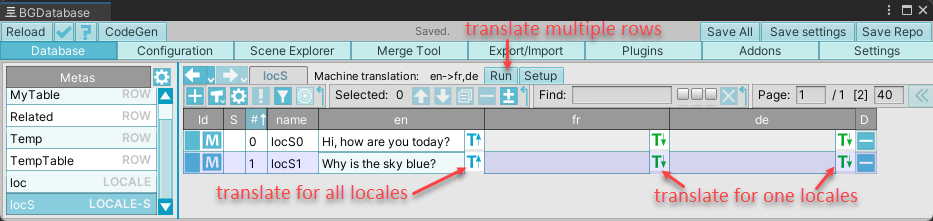
- Click "Run" to translate several rows. Click T↑ to translate one row to all locales. Click T↓ to translate current row to one locale
- After completing the translations, you can free up your GPU VRAM by clicking the "Unload the model" button.
